[置顶]玩AI必装的组件,CUDA和C++桌面开发 CUDA安装:CUDA 已经成为高性能计算领域的一个重要工具,尤其是在深度学习和人工智能领域,其高效的数据处理能力使其成为不可或缺的技术之一,所以很多AI工具都需要CUDA运算,因此CUDA也是玩AI必须要装的一个软件,点击下面链接,根据你系统相应下载安装即可。https://developer.nvidia.com/cuda-downloads
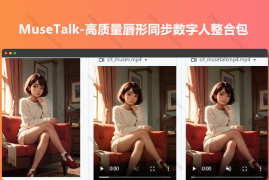
VIP免费 MuseTalk-高质量唇形同步数字人整合包 离线终端版 MuseTalk 是由腾讯团队开发的先进技术,它是一个实时的音频驱动唇部同步模型。该模型能够根据输入的音频信号,自动调整数字人物的面部图像,使其唇形与音频内容高度同步。这样,观众就能看到数字人物口型与声音完美匹配的效果。MuseTalk 特别适用于256 x 256像素的面部区域,且支持中文、英文和日文等多种语言输入。在NVIDIA Tesla V100显卡上,MuseTalk 能够实现超过每秒30帧的实时推理速度。此外,用户还可以通过调整面部区域的中心点,进一步优化生成效果。
VIP免费 SenseVoice-情感语音识别整合包 离线终端版 SenseVoice是由阿里巴巴集团开源的音频基础模型,专注于高精度的多语言语音识别、情感辨识和音频事件检测。该模型采用超过40万小时的数据训练,支持超过50种语言,识别效果上优于Whisper模型。SenseVoice具备以下核心功能:多语言识别:支持超过50种语言的语音识别,包括中文、粤语、英语、日语和韩语等,识别准确度在中文和粤语上提升超过50%。情感识别:具备优秀的情感识别能力,能够在多种风格数据上达到或超过当前最佳情感识别模型的效果。声音事件检测:支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件的检测。高效推理:SenseVoice-Small模型采用非自回归端到端框架,具有极低的推理延迟,处理10秒音频仅需70毫秒,比Whisper-Large快15倍。
VIP免费 Hallo-让图片说话,数字人说话整合包 离线终端版 Hallo 是由百度、复旦大学、苏黎世联邦理工学院,南京大学等机构共同研发的 AI 对口型肖像视频生成框架。它能够根据语音输入,生成逼真且动态的肖像图像视频,实现语音与视觉输出的同步。该技术通过分析语音输入,同步生成人像的面部动作,包括嘴唇、表情和头部姿势,最终生成效果惊艳的头像数字人。