
阿里巴巴开源的音频理解模型SenseVoice,它通过先进的深度学习技术,实现了多语言语音识别、情感识别和声学事件检测等功能,为开发者提供了强大的音频处理能力。
AI大部分项目需要CUDA和C++桌面开发组件支持,请点击这里按指导安装。对显卡要求也高,非Nvidia独立显卡电脑,不建议涉足AI项目。最后就是AI项目对中文不友好,所以无论文件名,素材名和路径名一律使用英文。
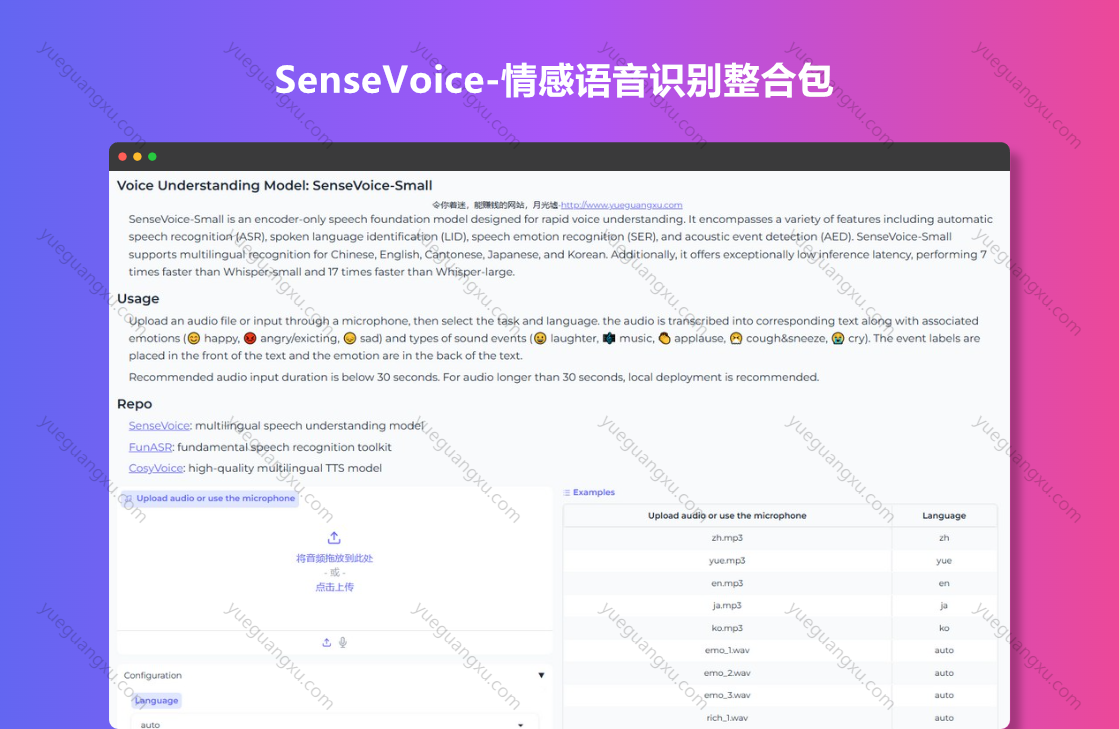
项目介绍:
SenseVoice是由阿里巴巴集团开源的音频基础模型,专注于高精度的多语言语音识别、情感辨识和音频事件检测。该模型采用超过40万小时的数据训练,支持超过50种语言,识别效果上优于Whisper模型。SenseVoice具备以下核心功能:
多语言识别:支持超过50种语言的语音识别,包括中文、粤语、英语、日语和韩语等,识别准确度在中文和粤语上提升超过50%。
情感识别:具备优秀的情感识别能力,能够在多种风格数据上达到或超过当前最佳情感识别模型的效果。
声音事件检测:支持音乐、掌声、笑声、哭声、咳嗽、喷嚏等多种常见人机交互事件的检测。
高效推理:SenseVoice-Small模型采用非自回归端到端框架,具有极低的推理延迟,处理10秒音频仅需70毫秒,比Whisper-Large快15倍。
使用方法:
把压缩包解压后,双击start.bat文件即可,或者右键点击选择打开。
配置要求:
操作系统:Windows 10/11 64位
显卡:4G或以上显存的英伟达(NVIDIA)显卡

