
CosyVoice,阿里巴巴开源的先进语音合成技术。支持多语言、音色克隆和情感控制,为开发者提供全栈的语音生成解决方案,推动语音交互技术的边界。
AI大部分项目需要CUDA和C++桌面开发组件支持,请点击这里按指导安装。对显卡要求也高,非Nvidia独立显卡电脑,不建议涉足AI项目。最后就是AI项目对中文不友好,所以无论文件名,素材名和路径名一律使用英文。
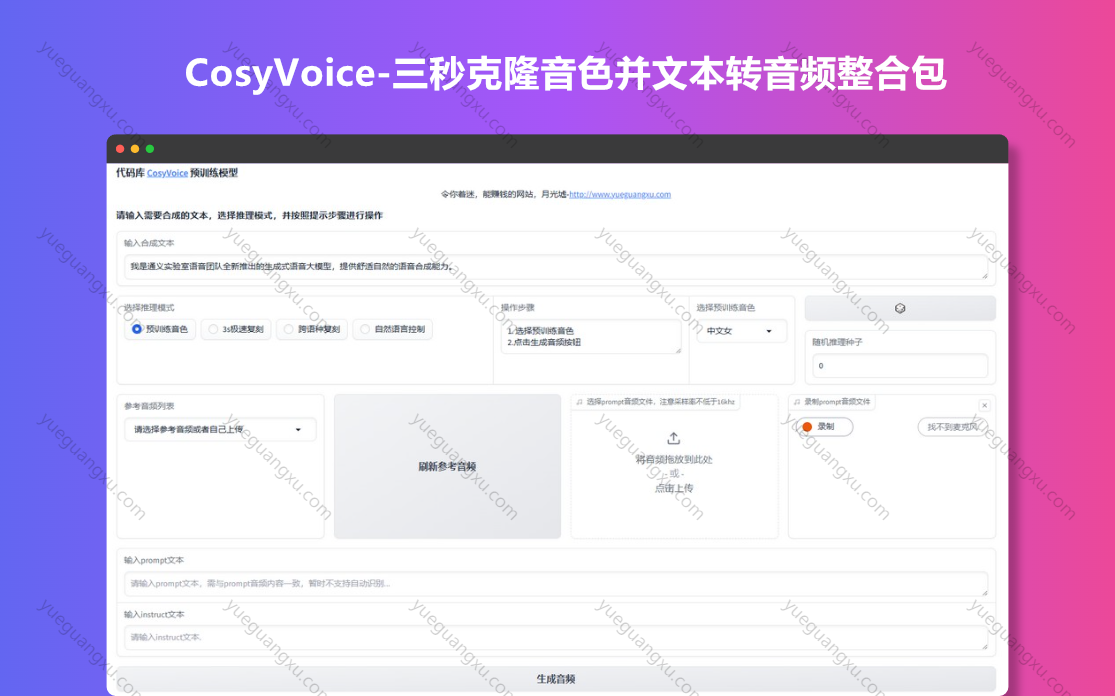
项目介绍:
CosyVoice是由阿里巴巴集团的通义实验室开源的多语言语音合成模型,它通过深度学习技术实现了自然语音的生成。该项目的主要特点包括:
多语言支持:CosyVoice能够生成包括中文、英文、日文、粤语和韩语在内的多种语言的语音。
多种推理模式:模型支持零样本推理、跨语言推理和指令推理等多种模式,提供了灵活的语音合成能力。
音色克隆:CosyVoice支持one-shot音色克隆,仅需3到10秒的原始音频样本,即可生成具有相似音色的语音,包括韵律、情感等细节。
情感控制:模型能够通过自然语言或富文本输入实现对情感和韵律的精细控制,使得合成语音更加富有表现力。
全栈能力:CosyVoice提供了从数据准备、模型训练到模型部署的全流程支持,方便开发者快速上手和应用。
使用方法:
把压缩包解压后,双击运行-CosyVoice-300M-Instruct.bat文件即可,或者右键点击选择打开。
配置要求:
操作系统:Windows 10/11 64位
显卡:6G或以上显存的英伟达(NVIDIA)显卡

