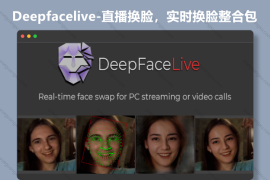
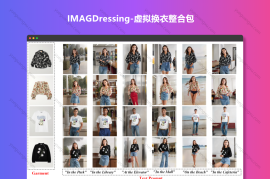
DeepFaceLive是由开发者Iperov创建的一个强大的实时面部捕捉和重建工具。它使用深度学习算法来追踪并再现人脸的细微表情,使得用户能够将这些动态表情应用到3D模型或其他数字媒体上。DeepFaceLive的核心技术基于卷积神经网络(CNN),通过训练大量的面部图像数据,学会了识别和跟踪面部特征点的能力。一旦捕获了这些特征点,软件就能实时地生成3D模型,并根据真实脸部的变化进行同步更新。DeepFaceLive的主要特点包括:高精度的面部捕捉和重建能力。实时性能,即使在较低配置的电脑上也能流畅运行。易用性,界面简洁,设置简单,适合初学者快速上手。兼容性强,支持多种输入设备和输出格式。DeepFaceLive的应用场景广泛,包括但不限于:实时面部动画:将面部表情映射到3D角色或游戏中。视频编辑:在视频后期制作中进行面部替换或添加特效。教育与演示:创建吸引人的虚拟形象进行教学或产品演示。娱乐与直播:在Twitch、YouTube等平台增加直播的互动性和趣味性。